Adventures in book analysis
In my previous post, Contributing to iText, I talked about my use of a great Java library called iText that lets you create and read PDF files. This is a post explaining the project, Adventurer, that I was working on which uses iText.
All the way back in December 2012 I backed a Kickstarter project by Ryan North for a choose your own adventure version of Hamlet called To Be Or Not To Be: That Is The Adventure. I pledged $35 to the project with the hopes of getting a signed physical book, some rad temporary tattoos as well as a DRM-free digital copy of the book. You can read more about the book over on Wikipedia.

In August 2013 I got the digital copies of the book, though I held off reading those versions for a couple of weeks while enjoying the physical book. Reading the physical book was great fun, there’s so much content and despite being based on what I’d consider fairly dry original material (Shakespeare was never my kind of thing) Ryan has done a fantastic job of modernising it and making it fun to read and play with.
This blog post isn’t a review of the book however, it’s about the project it inspired me to make. While the book was great fun to read it’s also fun to flick through and look at some of the crazy endings that may happen. Unfortunately there’s no easy way to find out how to get to some of these endings, and while playing through the book is very fun, sometimes you just want to find out the fastest route to some page you flicked past once that looked funny, and that’s where my project comes in.
The digital DRM-free copy of the book I received came in a few flavours, ePUB, Mobi and 2 PDFs (one regular resolution and 16MB, the other retina resolution and 88MB).
My thinking was that with these files I could parse the book into a database of some form, link pages together by the text on some paging saying “Turn to page X” and then write an algorithm to work back from a page I chose to find the routes I could take to get there.
Plan 1
I have done some software development to alter PDFs before using iText so I figured that I should stick with what I know and have my software analyse the PDF. I wrote a little proof of concept program in late 2014 to see if I could parse the page content, which I could. I initially started by reading the pages text content and using a regular expression to find the page links but soon decided it was a bad idea with all the edge cases and left the project for a while.
It’s now been a while since I picked up the physical book, but something inspired me to take another look at the project and try some other methods to learn how to work with iText better.
Plan 2

The first time I had run a regular expression over the entire page content but that proved inefficient and brittle. After looking at the book I noticed how all the links to other pages were always in a different font style to the rest of the page.
iText lets you define a TextExtractionStrategy which you can use to listen to events that call for items rendered on-screen by the PDF, such as images and text, and handle them however you see fit. For my plan I wrote a TextExtractionStrategy that would group all text render calls by the font details for the text to be rendered. This way I would have a list of text blocks and hopefully my “turn to page” links would be fairly self-contained.
Unfortunately this still meant looking for the links using a regular expression and the regular expression wasn’t working for all links. It also didn’t seem like an ideal way to find the link when I knew the links in the PDF were clickable, so there must be some deeper format-level link I could take advantage of.
Plan 3
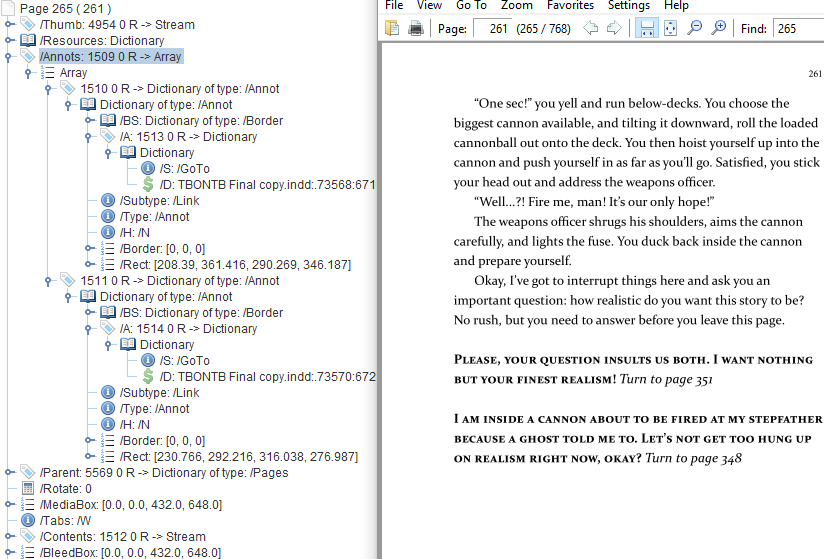
With thoughts of PDF page links in mind I did some research and dug through the books PDF with RUPS (a tool made by iText for inspecting the underlying content of a PDF), and found out about page annotations. The page links in the PDF for the book I had weren’t related to the text content on the page. Instead annotations are rectangle areas on the page, in this case the rectangles lay over the top of the link text, giving the appearance of a clickable link.
Annotations can have subtypes, but the only type I needed to be interested in were links. In the screen shot above you can see how two links, shown on the page to the right, show up as an array of annotations on the page object. Each annotation is a type “/Annot” and a subtype “/Link” with a dictionary on it containing a destination with key “/D” which is an indirect link to another page.
Looking promising I wrote some code to replace the old regular expression code and gave it a go. It worked perfectly first time!
Database
In my original thoughts I was going to go down one of two routes:
- Load all data into memory and write my own algorithms for route finding
- Load it into a relational database and write some SQL to find the page routes
But after a little research and a few software development conferences where I’d been hounded by graph database vendors to give it a go I figured perhaps I might finally try using one.
I chose Neo4j as I’d written the project in Java already, it could run embedded and not need a server setup and most importantly they had given me some stickers a few years ago at QCon London which I remember being decent quality, so the software might be too.
Working with Neo4j was actually very easy. I’m probably not using it in the most efficient way, but it worked well enough.
At the start of the program I open the database and create a node for each page in the PDF. The page nodes get properties for the PDF page number as well as the book page-label. Once all the pages are in the database as un-linked nodes I process each node looking for annotations. Any found should create a link between nodes (if the link wasn’t already there) and if there’s no link annotations at all on the page then I add a continue relationship to the next page.
If the page content is just an image or “THE END” I add a label to the node to mark it as an ending. I also add labels to mark the sub-book as well as pages to ignore (prefaces).
Querying
Once the database is populated I can finally start to run some queries to do what I originally wanted to with this project: Find routes to endings.
Neo4j has a query language called Cypher and I used this project as an opportunity to learn it and test it out on some data I knew well and could see errors easily.
The first query I ran was to return all the nodes and relationships I had put in to Neo4j and check that the data was all in there. The node count should be the same as the book page count, relationship count should be at least the same as the page count though ideally some factor higher as some pages link to multiple pages.

The cypher query for this was simply MATCH (n) RETURN n which matches and returns all nodes, and by extension their relationship information.
Next I ran a simple cypher query to get all the data for the sub-book inside To Be Or Not To Be, called “The Murder of Gonzago”.
MATCH (n:SubBook) RETURN n
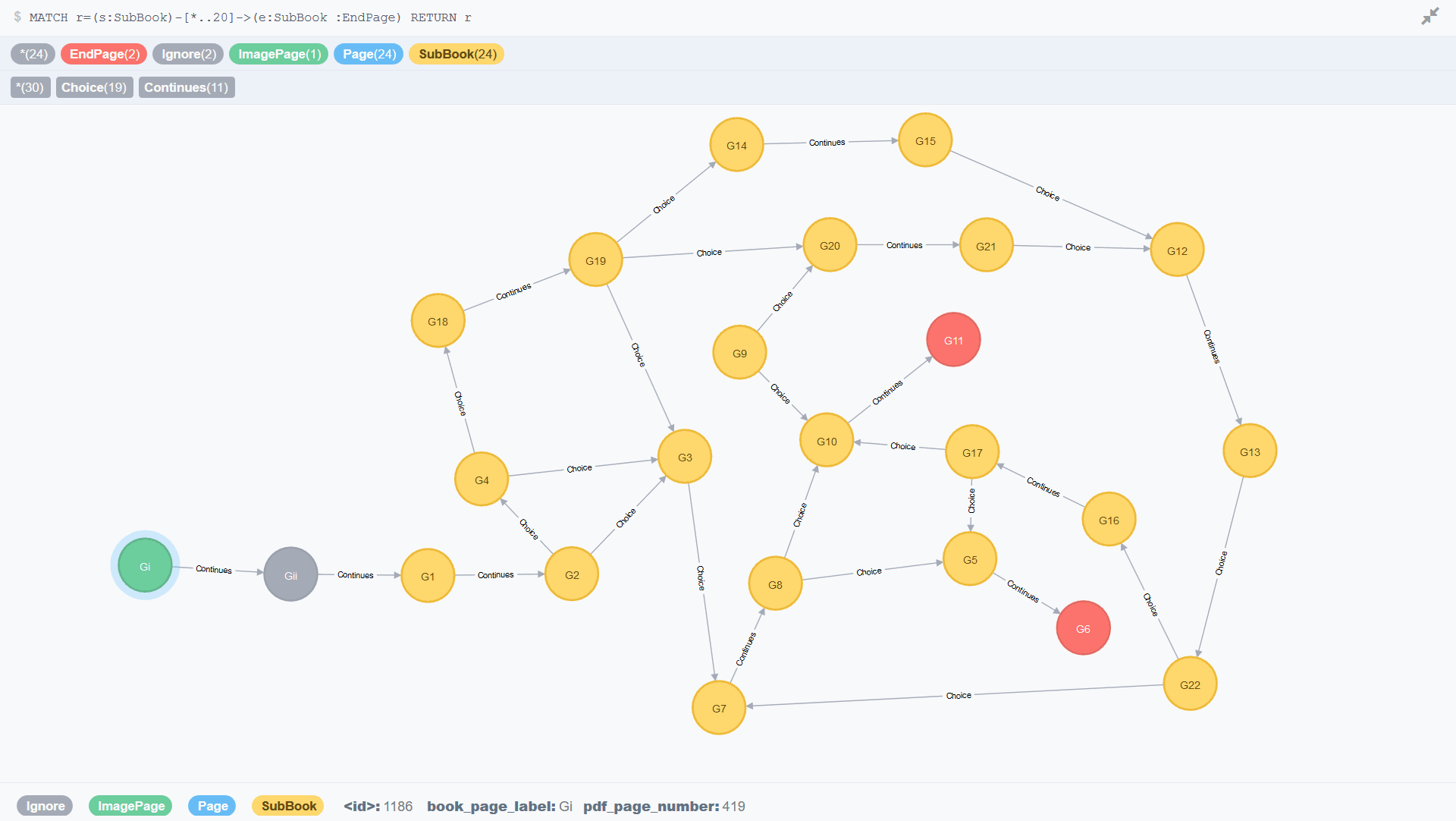
The query matches all nodes with a SubBook label on them and I’m showing them using the default Neo4j front end as a series of circles (nodes) and lines (relationships).
The green node is an image page, the cover of the sub-book. Grey pages are pages to ignore, the preface. Yellow nodes are regular pages and red nodes are ending pages. The relationships have “Choice” or “Continues” on them and arrow directing flow. Click the image to see it full size.
This looked correct so I decided to attempt mapping a route to one of my favourite endings:
MATCH r=(s:Page)-[*..20]->(e:Page {book_page_label: "197"}) RETURN r
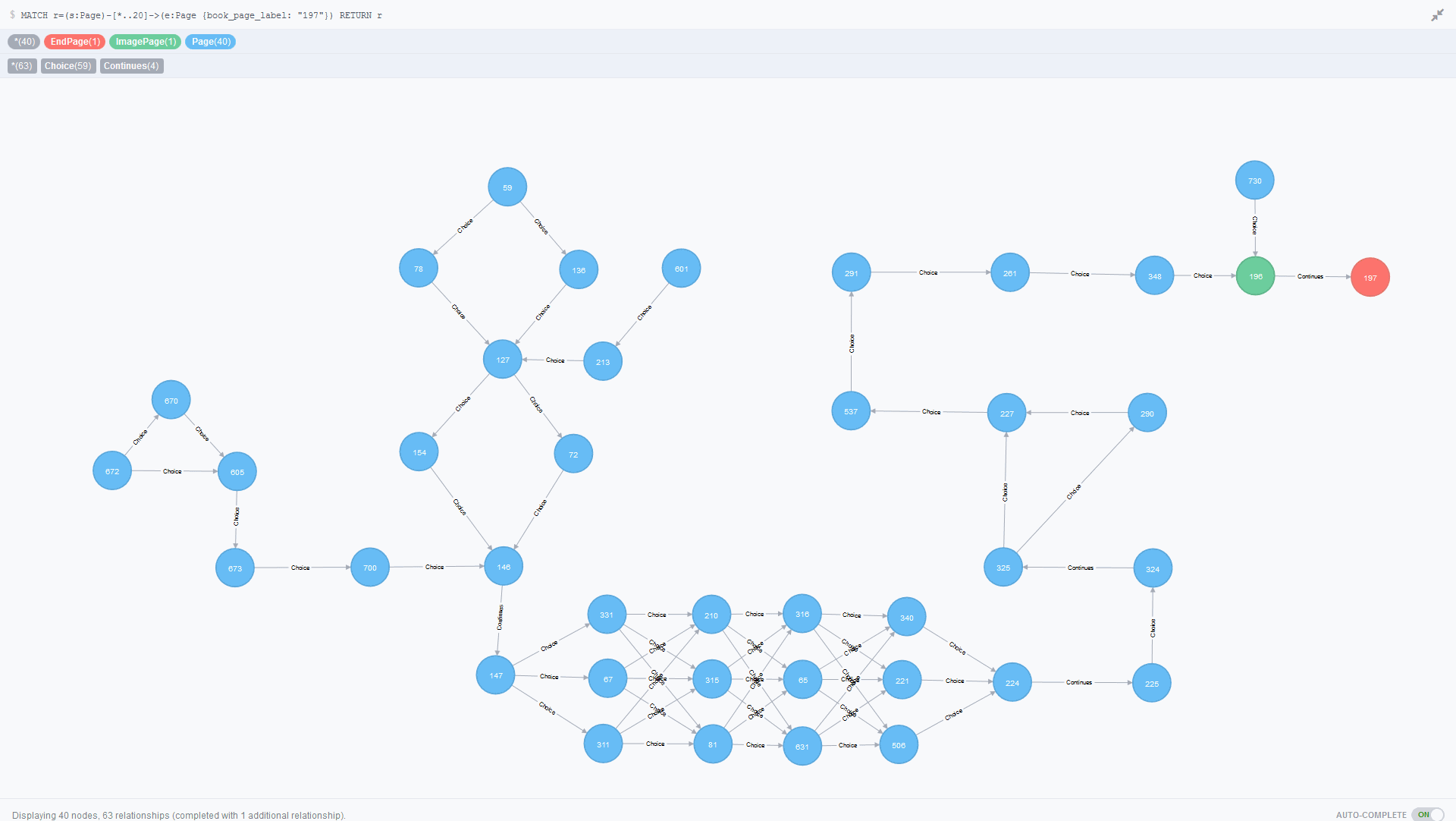
This query matches all nodes with the Page label on them that are up to 20 nodes away from a Page node with the book_page_label property set to 197. Page 197 is an excellent ending image where Hamlet is seen riding Claudius as a skateboard over the castle walls.
To get to this point in the book you must have taken charge of a pirate ship so that you can get fired out of the cannon at the castle walls… this is not in the original play but it’s much more fun and definitely one of my favourite endings to get from the book.
To get the pirate ship you have to fight the pirate captain through several pages where you are given 3 choices of how to attack the captain. The block of choices making up the fight shows up clearly on the above image of the graph near the bottom as a series of 3 pages linking to another 3 pages which is actually your swashbuckling.
Epilogue
After a few more queries and some more renewed fun reading the book I called this project finished. The code ended up very special-cased for this book and it still very rough but it served its purpose in helping me get to some of the illustrated endings I wanted to and making me pick the book up again.
While taking to some colleagues about it and showing some people who I knew had shown an interest in Neo4j and other graph database before I ended up giving a company-wide presentation at one of the regular Fivium Developer Meetings. Since then a few people in Fivium have gone on to use Neo4j in personal side projects and even find some applicable uses in our business products.
As I knew Ryan North, the author of this excellent adventure book, was not only a comic creator but a programmer himself I figured I’d send him a link to see what he thought: